LLMのモデルサイズと回答精度の関係
2024年10月1日

目次
1. エグゼクティブサマリ
本記事では、2024年11月25日に発行された「Larger and more instructable language models become less reliable(より大規模でより指導可能な言語モデルは信頼性が低くなる)」についての要約と考察を述べます。
近年、大規模言語モデル(LLMs)はそのパラメータ数やデータ量の増加、そして人間のフィードバックを通じた微調整により、より強力で指示に従いやすいものへと進化してきました。しかし、この論文では、LLMsが大規模化し、指示適応性が向上するにつれて、その信頼性がむしろ低下する可能性があることが示されています。具体的には、人間にとって容易なタスクであってもモデルが誤答を生成する「難易度不一致」や、モデルが質問を回避せずに誤った回答を提供する「タスク回避の欠如」、そして異なる表現の質問に対する応答の不安定性が指摘されています。これらの結果は、AIの設計と開発において、特に高リスクの分野での信頼性を確保するための根本的な見直しが必要であることを強調しています。
2. 背景と現状分析
大規模言語モデル(LLMs)は、多くのパラメータと膨大なデータセットを用いてトレーニングされ、人間のフィードバックを通じて微調整されてきました。この「スケールアップ」と「シェイプアップ」により、LLMsは教育、医療、科学、行政など、多岐にわたる領域で日常的に利用されるようになっています。
一般的な認識として、モデルがより大規模化し、指示適応性が向上すれば、その性能も信頼性も向上すると思われがちです。しかし、現実には、ユーザーはモデルが簡単なタスクでも誤答を生成し、期待に反する結果を得ることが多々あります。例えば、初期のモデルは簡単な加算問題ですら正答できませんでしたが、ユーザーはその限界を理解し、モデルに過度な期待を抱くことはありませんでした。しかし、最新のモデルは複雑な計算もこなす一方で、簡単な計算で誤答することもあり、ユーザーの信頼を損なっています。
このような状況下で、モデルの信頼性、すなわちユーザーが予測可能なパターンでモデルのエラーを理解し、対応できる能力が重要となっています。本論文では、この信頼性が大規模化と指示適応性の向上に伴い、どのように変化してきたかを分析しています。
3. メインコンテンツ
研究の目的:
本研究の主な目的は、LLMsのスケールアップ(モデルの大規模化)とシェイプアップ(人間のフィードバックによる微調整)が、モデルの信頼性にどのような影響を及ぼすかを明らかにすることです。具体的には、以下の3つの要素に焦点を当てています:
1. 難易度不一致:モデルのエラーが人間の感じるタスクの難易度と一致しているか。
2. タスク回避:モデルが回答できない質問に対して適切に回避行動をとるか。
3. プロンプトの安定性:同じ質問を異なる表現で与えたときに、一貫した応答を生成できるか。
研究対象とモデル:
本研究では、以下の3つの主要なLLMファミリーを分析対象としました:
・GPTシリーズ(OpenAI):最新の性能を持つモデルで、LLMエコシステムに大きな影響を与えています。
・LLaMAシリーズ(Meta):モデルの重みが公開されており、スケールアップとシェイプアップの影響を詳細に分析できます。
・BLOOMシリーズ(BigScience):科学コミュニティから生まれたオープンなプロジェクトで、多言語対応のモデルを提供しています。
各ファミリー内で、原型モデル(シェイプアップされていないモデル)と、人間のフィードバック等で微調整されたシェイプアップモデルを比較することで、スケールアップとシェイプアップの効果を分析しました。
ベンチマークと難易度指標:
モデルの評価には、以下の5つのベンチマークを使用しました:
・加算(Addition):1桁から100桁の数値の加算問題。
・アナグラム(Anagram):3文字から20文字の単語の文字を並べ替えて元の単語を再構成する問題。
・地域(Locality):指定された都市から一定距離以内で最も人口が多い都市を尋ねる地理的知識問題。
・科学(Science):基本的な科学知識から高度な大学院レベルの問題までを含む多岐にわたる質問。
・変換(Transforms):情報の再構築やデータフォーマットの変更など、実用的な変換タスク。
これらのベンチマークに対して、人間が感じるタスクの難易度を評価するための難易度指標を設定しました。例えば、加算では繰り上がりの回数、アナグラムでは文字数、地域では都市の知名度の逆数を難易度として設定しました。
また、回答の評価には「正答(correct)」「誤答(incorrect)」「回避(avoidant)」の3つのカテゴリーを用いました。
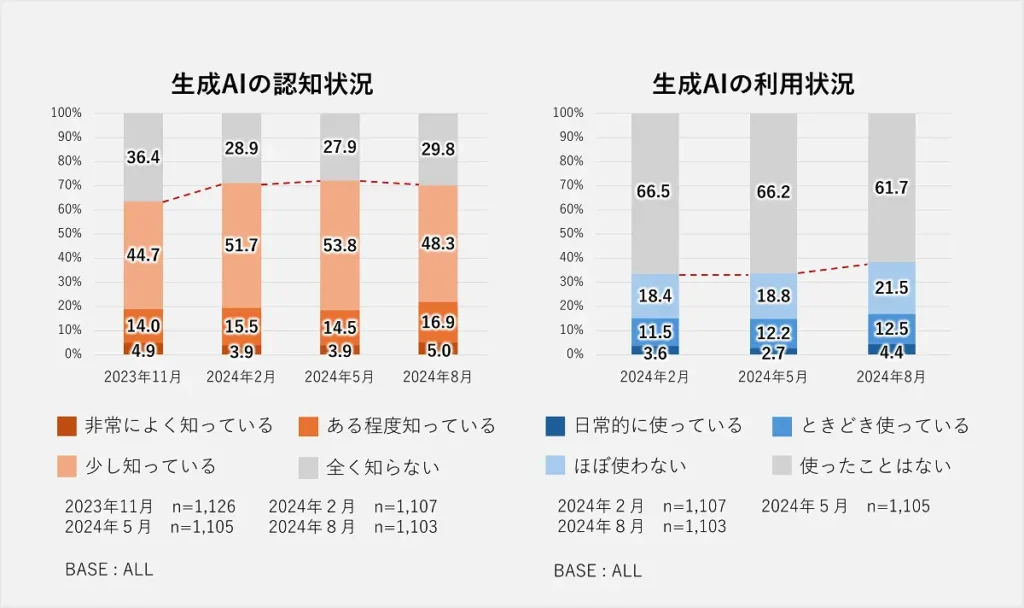
3.2 業務への影響と導入拡大における課題
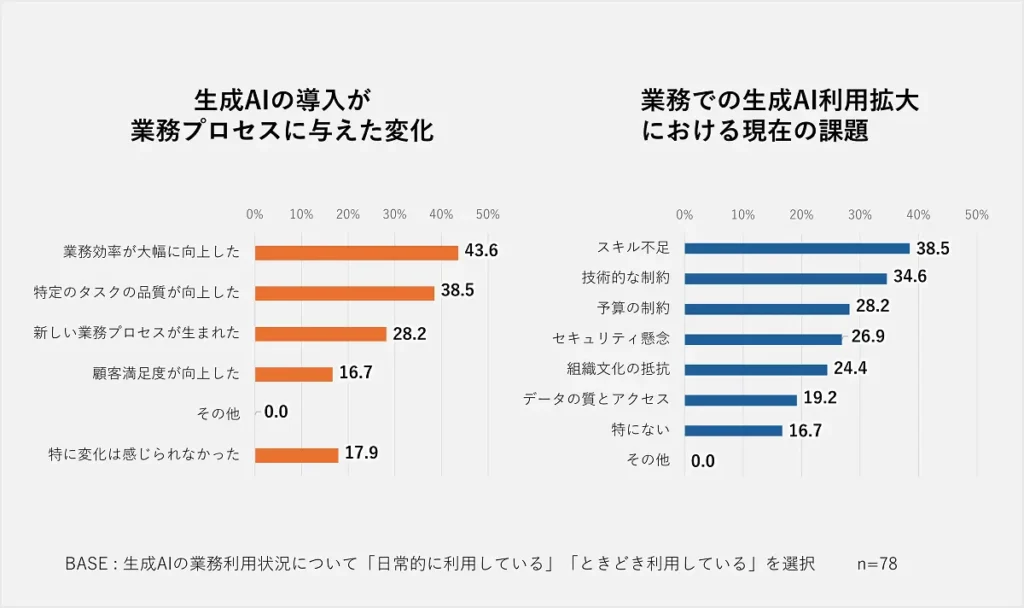
生成AIを業務で利用しているユーザーからは、以下のようなポジティブな影響が報告されています:
・業務効率の大幅な向上(43.6%):タスクの自動化や処理時間の短縮が実現。
・特定タスクの品質向上(38.5%):ミスの減少や品質の一貫性が向上。
また、生成AIの更なる導入・活用を妨げている主な課題は以下の通りです:
・スキル不足(38.5%):生成AIを効果的に使いこなす人材の不足。
・技術的な制約:既存システムとの統合やセキュリティ面での課題。
・予算の制約:初期導入費用や運用コストへの懸念。
4. 今後の展望と戦略的示唆
4.1 人材育成と組織内教育
スキル不足を解消するために、以下の施策が有効です:
・社内トレーニングプログラムの実施:生成AIの基礎から応用までを学べるカリキュラムを提供。
・専門人材の採用:データサイエンティストやAIエンジニアの積極的な採用。
・知識共有の促進:成功事例やノウハウを組織内で共有。
4.2 技術的・予算的課題への対応
技術的な制約や予算の問題に対しては、以下の戦略が考えられます:
・クラウドサービスの活用:初期投資を抑えつつ、高度なAI機能を利用可能。
・オープンソースの活用:コスト削減とカスタマイズ性の向上。
・パートナーシップの構築:専門企業との連携で技術的課題を解決。
4.3 戦略的な活用領域の拡大
生成AIの効果を最大化するために、新たな活用領域を探求します:
・顧客サービスの強化:チャットボットやパーソナライズされた提案。
・製品開発の効率化:アイデア創出やデザインの自動化。
・市場分析と予測:ビッグデータを活用したトレンド予測。
5. 結論とキーテイクアウェイ
生成AIは、業務効率化や品質向上に大きな可能性を秘めています。しかし、その潜在能力を引き出すためには、スキル不足や技術的・予算的な課題を克服する必要があります。
キーテイクアウェイ:
・認知度と利用率のギャップを埋める:教育と啓発活動が鍵。
・人材育成が成功のカギ:社内教育と専門人材の確保が必要。
・技術的・予算的課題を戦略的に解決:クラウドサービスやパートナーシップの活用。
・新たな活用領域の開拓で競争力を強化:生成AIの多面的な活用でビジネス価値を最大化。
企業はこれらの戦略を積極的に取り入れることで、生成AIの持つポテンシャルを最大限に活用し、市場での競争優位性を確立することができます。
引用元:
・GMOインターネットグループ社「AIトレンドに関する自主調査」