Meta、無料で商用可のLLM「Llama 3.2」について
2024-09-27

目次
1. エグゼクティブサマリ
Llama 3.2は、Metaによって開発された最新の大規模言語モデル(LLM)であり、初めて画像処理能力を備えたマルチモーダルモデルとして登場しました。この革新により、テキストと画像の両方を統合的に理解し、より高度なタスクを遂行できる能力を持ちます。さらに、軽量化モデルの開発により、スマートフォンやエッジデバイスなどの制約された環境でも高性能を発揮できる点が特徴です。この記事では、Llama 3.2の技術的背景、現在の活用状況、そして今後の展望について詳しく分析します。
2. 背景と現状分析
近年、人工知能(AI)技術は飛躍的に進化し、大規模言語モデルが多くの分野で広く活用されています。従来のLLMは主にテキスト処理に特化していましたが、企業や研究者のニーズが多様化する中で、マルチモーダル(テキストと画像の統合)への関心が高まっています。Llama 3.2はこのトレンドに応じて、以下のような点で従来モデルを上回る性能を実現しています。
マルチモーダル対応:
Llama 3.2は、初めて画像認識とテキスト生成を統合する能力を持つモデルです。画像エンコーダを言語モデルに統合するためのアダプタ層を採用し、画像とテキストの一貫性を保ちながら高精度な処理を実現しています。
モデルの軽量化と適応性:
1Bおよび3Bパラメータの軽量モデルは、知識蒸留とプルーニング(不要な部分を削減する技術)を組み合わせることで、より少ない計算資源で高性能を発揮できます。これにより、スマートフォンやエッジデバイスでもローカルでの利用が可能となりました。
オープンソース戦略:
Llama 3.2はオープンソースで提供されており、開発者や企業が自由にダウンロードしてローカルで実行、さらに独自の用途に合わせてファインチューニング(追加学習)できる点が特徴です。これにより、データプライバシーの懸念がある企業にとっても導入しやすいモデルとなっています。
3. メインコンテンツ
3.1 Llama 3.2の技術的革新
Llama 3.2は、以下の技術的な改良を通じて従来のモデルを超える性能を発揮しています。
画像とテキストの統合処理:
Llama 3.2は、画像エンコーダを言語モデルに統合することで、画像とテキストの双方を同時に理解・処理できます。例えば、図やチャートの解釈、科学的図面の理解においても高い性能を示しています(図1)。
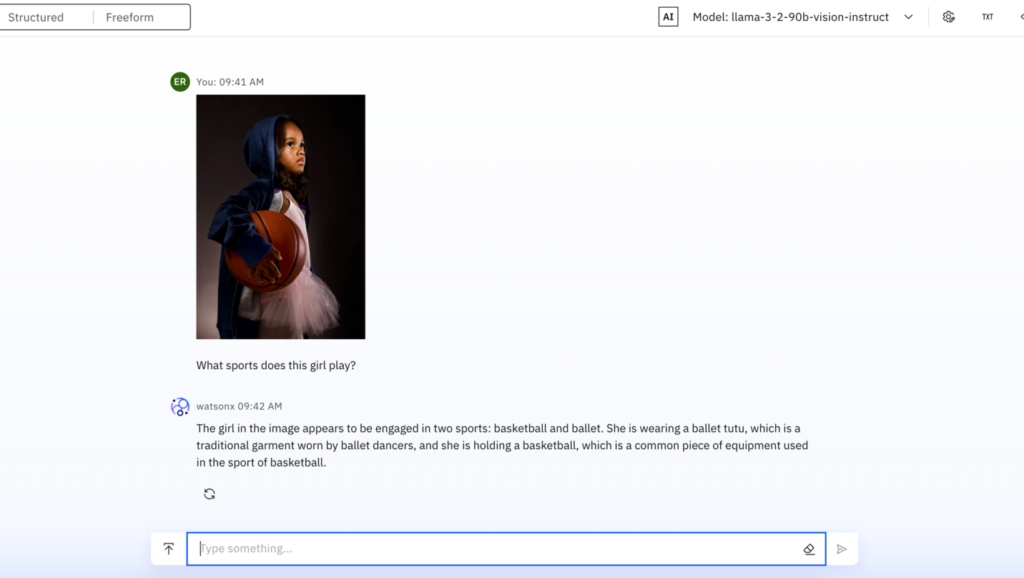
図1: Llama 3.2による画像の理解
軽量化モデルの開発:
1Bおよび3Bモデルは、プルーニング技術を活用し、メモリ使用量を大幅に削減することに成功しました(図2)。これにより、モバイル端末でも使用可能なモデルとなり、ユーザーのプライバシー保護やセキュリティ強化にも貢献しています。
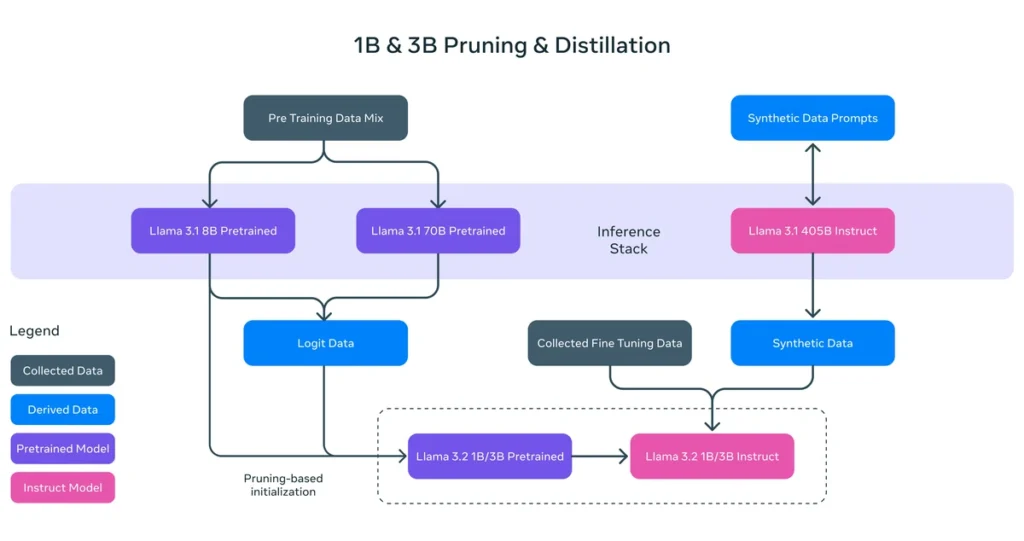
図2: プルーニングと知識蒸留の全体像
軽量化モデルの開発:
1Bおよび3Bモデルは、プルーニング技術を活用し、メモリ使用量を大幅に削減することに成功しました(表1)。これにより、モバイル端末でも使用可能なモデルとなり、ユーザーのプライバシー保護やセキュリティ強化にも貢献しています。
3.2 実世界での活用事例
データ分析と分類:
レシートのデータ分析や商品データの分類など、画像とテキストを統合して情報を抽出・整理するタスクにおいて有効です。これにより、財務、医療、リテールなど多岐にわたる業界での活用が見込まれます。
AIエージェントの構築:
Llama 3.2のマルチモーダル能力を活かして、ウェブブラウジングや商品検索などのタスクを自動で実行するAIエージェントを構築することが可能です。
4. 今後の展望と戦略的示唆
多様なデータモダリティの統合:
Llama 3.2の次の進化として、音声やセンサーデータ、さらには特定の専門領域(金融データや医療画像)への適用が期待されます。これにより、さらに多機能なAIシステムが構築され、業務効率の向上や新しいビジネスモデルの創出につながるでしょう。
プライバシーとセキュリティの強化:
データプライバシーの懸念から、ローカルでのモデル実行を可能にする軽量化モデルの需要が高まっています。特に、Llama 3.2のようなモデルは、オフライン環境でのデータ処理を可能にし、セキュリティリスクを低減する効果が期待されます。
業界別の特化モデルの開発:
今後は、医療、法律、製造業など特定の業界向けに最適化された特化型Llamaモデルの開発が進むと予想されます。これにより、各業界のニーズに対応したソリューションが提供され、より高い精度での業務支援が可能となるでしょう。
5. 結論とキーテイクアウェイ
Llama 3.2は、従来の大規模言語モデルを超えた革新的なマルチモーダルAIモデルであり、特に画像とテキストの統合理解において顕著な成果を上げています。軽量化モデルの登場により、より広範なデバイスでの利用が可能となり、実用性が飛躍的に向上しました。今後、さらに多様なデータモダリティの統合が進む中で、Llama 3.2は新たな産業革命をもたらす可能性を秘めており、ビジネスや研究分野における応用が期待されます。
キーテイクアウェイ:
・Llama 3.2はマルチモーダル対応により、テキストと画像を同時に処理可能なモデルである。
・軽量化されたモデルバリアントにより、モバイルやエッジデバイスでの利用が可能。
・データプライバシーやセキュリティ面での優位性があり、業界別の特化モデル開発が今後の成長分野となる。
引用元:
・OpenLM.ai社「Llama 3.2: Integrating Vision with Language Models」
・WIRED「Meta Releases Llama 3.2—and Gives Its AI a Voice」
・Geeky Gadgets「New Meta Llama 3.2 Open Source Multimodal LLM Launches」
・IBM「Meta’s Llama 3.2 models now available on watsonx, including multimodal 11B and 90B models」
・Analytics India Magazine「Meta Launches Llama 3.2, Beats All Closed Source Models on Vision」
NITI について
私たちの使命は、最先端技術を最速で届け、実社会に革新をもたらすことです。最高水準のAI技術で、国内外の様々な実社会の課題解決に取り組みます。
私たちの使命は、最先端技術を最速で届け、実社会に革新をもたらすことです。
最高水準のAI技術で、国内外の様々な実社会の課題解決に取り組みます。
まずは気軽に、壁打ちしてみませんか?
私たちと壁打ちしてみませんか?話すことで視野が広がり、今後のアクションや解決策が見えてくることがあります。まずはお気軽にお声がけください。
私たちと壁打ちしてみませんか?
話すことで視野が広がり、今後のアクションや解決策が見えてくることがあります。
まずはお気軽にお声がけください。